
Startseite → GPU-Servergehäuse → Anwendungen
GPU Server Case Anwendungen
Stimmen Sie Ihre Arbeitslast auf die Anforderungen an das richtige GPU-Servergehäuse ab - Kühlung, PCIe-Erweiterung, Stromversorgung, Speicherung und Wartungsfreundlichkeit. Diese Seite behandelt KI-Training, KI-Inferenz, HPC und angrenzende GPU-beschleunigte Implementierungen.
Übersicht
Verwenden Sie diese Kontrollpunkte, bevor Sie eine Chassisfamilie auswählen:
- Profil der Arbeitsbelastung: Nachhaltiges Training vs. Bursty Inference vs. langlaufende HPC-Jobs.
- Anzahl der GPUs und Formfaktor: Dual-Slot, Kartenlänge/-höhe und Steckverbinderabstand.
- Thermisches Ziel: die Integrität des Luftstroms von vorne nach hinten, die Kapazität der Lüfterwände und das Design der Prallplatten.
- PCIe-Layout: GPUs + Hochgeschwindigkeits-NICs + Speicher-HBAs ohne Blockierung des Luftstroms.
- Operationen: Hot-Swap-Einschübe, werkzeugloser Zugang, Schienen und In-Rack-Service-Flow.
Anwendungen / Anwendungsfälle
AI-Ausbildung (LLM / CV / Multimodal)
Schmerzpunkte
- Thermische Drosselung bei anhaltender GPU-Last.
- Eine dichte Verkabelung und schwere Knoten verlangsamen die Wartungsarbeiten.
- GPUs + NICs konkurrieren um Platz und Luftstrom.
Anforderungen
- Lüfterwand mit hohem statischem Druck und Luftstromleitbleche.
- Sauberes Netzteil-Design für Multi-GPU-Stromversorgung.
- Vorderer Wartungszugang für Lüfter und Antriebe.
Wesentliche Metriken
- GPU-Kapazität und Abstände (Länge/Höhe/Breite).
- Kühlreserve bei anhaltender Nutzung.
- Wattleistung des Netzteils und Verfügbarkeit des GPU-Stromanschlusses.
- PCIe-Plan für x16-Steckplätze, Riser und NIC-Platzierung.
Empfohlene Konfiguration
- Gehäuse der 6U/8U-Klasse für höhere GPU-Dichte (abhängig von GPU-Größe und Thermik).
- Redundante PSU-Optionen, Lüfterwand und spezielle Ablenkungen.
- Hot-Swap-Einschübe an der Vorderseite für Betriebssystem und lokalen Cache.
KI-Inferenz (Edge/On-Prem)
Schmerzpunkte
- Begrenzte Regaltiefe und räumlich begrenzte Standorte.
- Höhere Umgebungstemperatur und Staub in gemischten Umgebungen.
- Sie benötigen schnelle Austauschzyklen für den Fuhrparkbetrieb.
Anforderungen
- Kompaktes Gehäuse mit stabilem Luftstrom und Frontzugang.
- Unterstützung für 1-4 GPUs plus Speicherschächte für Protokolle und Cache.
- Robuste Schienen/Handgriffe für häufigen Einsatz.
Wesentliche Metriken
- Fahrgestelltiefe und Schienenauszugsbereich.
- Kühlleistung bei höheren Umgebungsbedingungen.
- Leistungseffizienz bei angestrebtem Durchsatz.
- E/A und Anzeigen auf der Vorderseite für eine schnelle Fehlersuche.
Empfohlene Konfiguration
- Gehäuse der 4U-Klasse für kompakte GPU-Knoten (abhängig von GPU-Größe und Thermik).
- Hot-Swap-Einschübe für schnelle Wartungsarbeiten im Rack.
- Optionaler Staubfilter und verstärktes Frontdesign.
HPC (Simulation / Forschung / Wissenschaftliches Rechnen)
Schmerzpunkte
- Lang laufende Aufträge erhöhen die Kosten von Instabilität und Fehlern.
- Hochgeschwindigkeits-NICs konkurrieren mit GPUs um PCIe-Platz und Luftstrom.
- Verschiedene Labors haben unterschiedliche Standards für Racks und Wartung.
Anforderungen
- Vorhersehbarer Luftstrom von vorne nach hinten und Redundanzoptionen für Lüfter.
- Sauberes PCIe-Layout für GPUs + Hochgeschwindigkeitsnetzwerke.
- Werkzeugloser Zugang und wartbare Ventilator-/Antriebsarchitektur.
Wesentliche Metriken
- Anzahl der FHFL-Steckplätze und Ausrichtung der Riser.
- Bereitschaft und Freigabe der PCIe-Generation für NICs.
- Wärmespanne bei dauerhafter Nutzung des 100%.
- Redundanz der Netzteile und allgemeine Zuverlässigkeitsziele.
Empfohlene Konfiguration
- Gehäuse der 5U/6U-Klasse für ausgewogene Dichte und Erweiterung.
- Platz für GPUs + NICs bei minimaler Unterbrechung des Luftstroms.
- Optionale mittlere Lüfterhalterungen zum Schutz der NIC-/Speicherbereiche.
Rendering / VDI / Digitaler Zwilling
Schmerzpunkte
- Nachfragespitzen können zu Hotspots und Instabilität führen.
- Die hohe Benutzerdichte erhöht die Belastung durch Strom und Kühlung.
- Große Assets erfordern einen lokalen Cache oder schnelle Speicheroptionen.
Anforderungen
- Gleichmäßiger Luftstrom über alle GPUs mit Luftleitblechen.
- Hot-Swap-Einschübe für Cache- und Wartungseffizienz.
- Schienen, die für schwere GPU-Konfigurationen ausgelegt sind.
Wesentliche Metriken
- Abstand zwischen den GPUs und Konsistenz des Luftstroms.
- Anzahl der Laufwerksschächte und Backplane-Typ (SAS/SATA/NVMe).
- Auswahl des Netzteils und Redundanzstrategie.
- Frontblinker und Servicezeit.
Empfohlene Konfiguration
- 6U-Gehäuse für höhere GPU-Dichte (abhängig von GPU-Größe und Thermik).
- Redundante PSU-Option für Dauerbetrieb.
- Hot-Swap-Schächte an der Vorderseite für schnellen Austausch in Farmen.
GPU-Analytik & Datenpipelines (ETL / Video / Suche)
Schmerzpunkte
- Speicherbandbreite und PCIe-Topologie können zu Engpässen werden.
- Viele Laufwerke + GPUs erhöhen die Komplexität der Kabel und die thermische Kopplung.
- Ein 24×7-Betrieb erfordert schnelle und wiederholbare Wartungsarbeiten.
Anforderungen
- Backplane und Hot-Swap-Schächte für einen einfachen Betrieb.
- PCIe-Raum für GPUs + NICs + HBAs nach Bedarf.
- Luftstromschutz für GPU- und Laufwerksbereiche.
Wesentliche Metriken
- Anzahl der Laufwerksschächte und Schnittstellen (SAS/SATA/NVMe).
- Anzahl der FHFL-Steckplätze und interne Abstände.
- Frontanzeigen für Speicher- und Systemfehler.
- Zeit für den Austausch von Lüftern im Gestell.
Empfohlene Konfiguration
- 4U/5U-Gehäuse, wenn Sie mehr Buchten pro Rack-Einheit benötigen.
- Starke Lüfteranordnung und saubere Frontbedienung.
- Optionales kundenspezifisches Frontlayout für NVMe-lastige Designs.
Checkliste für die Auswahl
Validieren Sie das Chassis im Hinblick auf Ihre Einsatzbeschränkungen und zukünftige Upgrades.
| Kühlung | Lüfterwandkapazität, statischer Druck, Luftleitbleche, thermischer Spielraum der GPU, optionale flüssigkeitsdichte Montage. |
|---|---|
| Luftstrom | Integrität des Kanals von vorne nach hinten, Kontrolle von Kabel- und Steigleitungshindernissen, Staubminderung für raue Standorte. |
| PCIe | FHFL-Steckplätze, Riser-Layout, doppelt so breiter GPU-Raum, NIC/HBA-Raum, Gen4/Gen5-Bereitschaft. |
| Strom | Formfaktor des Netzteils (ATX/CRPS), Redundanz, Wattzahl, GPU-Anschlüsse, PDB-Design. |
| Laufwerksschächte | Anzahl der Hot-Swap-Schächte, Backplane-Typ (SAS/SATA/NVMe), Bandbreite und Luftstromtrennung. |
| Hauptplatine | Unterstützte Boardgrößen (EATX/CEB/ATX), Platz für CPU-Kühler, Platz für die Kabelführung. |
| Tiefe | Rackeinbau, rückseitiger Freiraum für Strom/Netzwerk, Kabelbiegeradius, Schienenauszugsbereich. |
| Schiene | Tragfähigkeit, werkzeuglose Montageoptionen, Standardisierung des Fuhrparks. |
| Wartung | Von vorne zugängliche Lüfter/Laufwerke, werkzeuglose obere Abdeckung, klare Anzeigen, modulare E/A. |
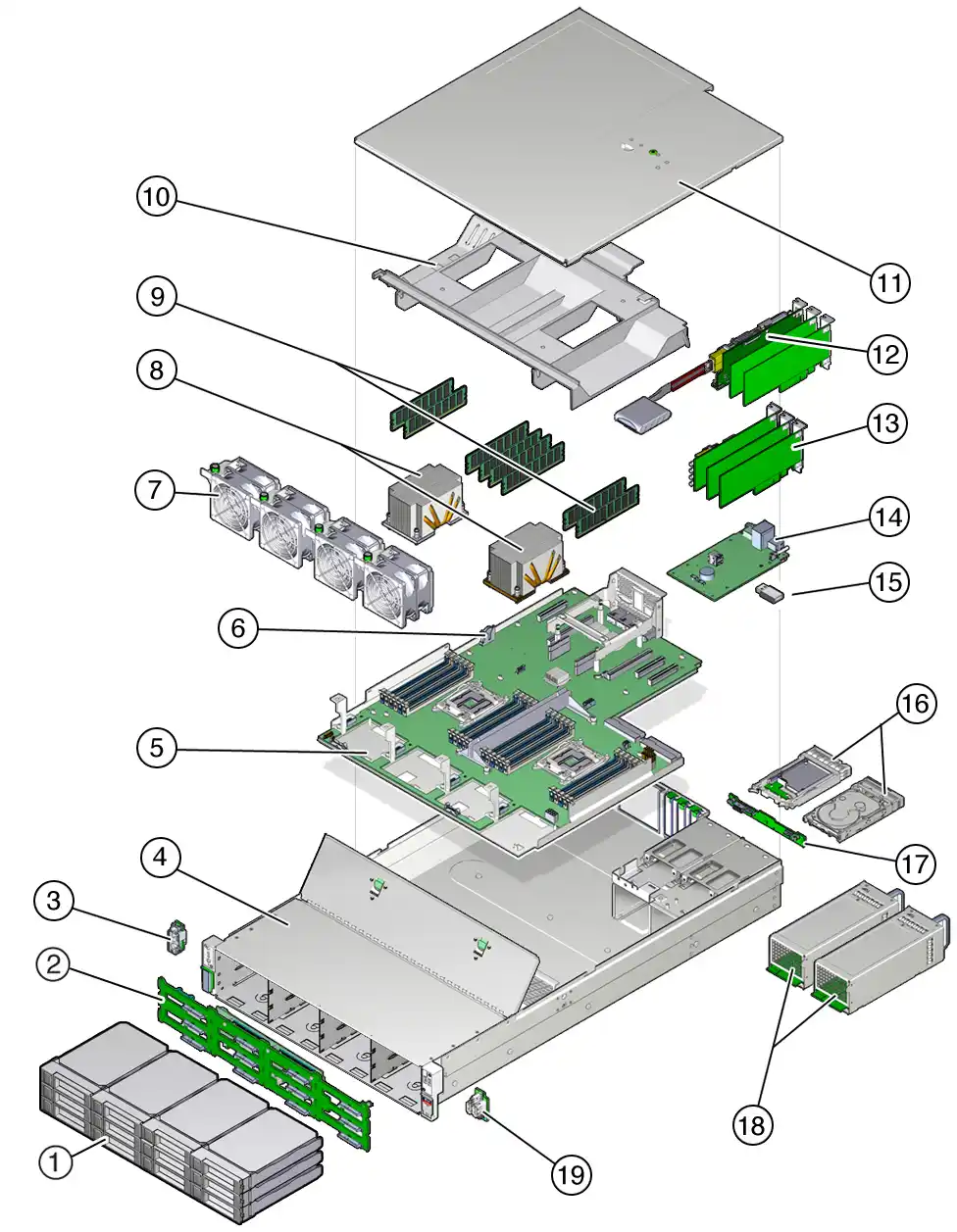
FAQ
Welche Gehäusegröße ist für das KI-Training am besten geeignet?
Gehen Sie von der Anzahl der GPUs, der GPU-Größe und den nachhaltigen thermischen Zielen aus. Trainingsknoten bevorzugen in der Regel eine höhere Luftstromkapazität und Wartungsfreundlichkeit. Prüfen Sie Ihre spezifische GPU-TDP, die Rack-Eingangstemperatur und das PCIe-Layout.
Worin besteht der Hauptunterschied zwischen dem Bedarf an Ausbildung und dem Bedarf an Fahrgestellen für Schlussfolgerungen?
Bei der Schulung wird der Schwerpunkt auf eine anhaltende Kühlung und eine höhere GPU-Dichte gelegt, während bei den Schlussfolgerungen oft die kompakte Bereitstellung, die Anpassung an die Racktiefe und die schnelle Wartung vor Ort im Vordergrund stehen. Beide erfordern ein sauberes PCIe- und Stromversorgungsdesign.
Wie vermeide ich thermische Drosselung in Multi-GPU-Servern?
Verwenden Sie ein Gehäuse mit einer Lüfterwand mit hohem statischem Druck, Luftleitblechen und freien Kabelwegen. Stellen Sie sicher, dass GPUs und NICs so platziert sind, dass der Luftstrom von vorne nach hinten erhalten bleibt und der Lufteinlass nicht behindert wird.
Welche PCIe-Details sollte ich vor der Bestellung bestätigen?
Bestätigen Sie die Anzahl der FHFL-Steckplätze, die Riser-Ausrichtung, die doppelte Breite der GPU und den Platz für Hochgeschwindigkeits-NICs und Speicher-HBAs. Richten Sie Gehäuse, Motherboard und Plattformtopologie frühzeitig aus, um Lane-Konflikte zu vermeiden.
Brauche ich redundante Netzteile für GPU-Server?
Redundante Netzteile werden für Cluster und Flotten empfohlen, bei denen die Betriebszeit im Vordergrund steht. Bemessen Sie das Netzteil so, dass es genügend Spielraum für den ungünstigsten Fall von GPU, CPU, Speicher, NICs und Lüftern bietet, und fügen Sie dann eine Sicherheitsspanne hinzu.
Wann sind Hot-Swap-Schächte wichtig?
Hot-Swap-Einschübe verkürzen die Servicezeiten im Multi-Node-Betrieb, insbesondere für Inferenzflotten, Rendering-Farmen und Analyse-Pipelines, bei denen ein schneller Laufwerkstausch und In-Rack-Service wichtig sind.
Kann iSTONECASE OEM/ODM-Anpassungen für spezifische Anwendungen unterstützen?
Zu den typischen Anpassungen gehören die Optimierung des Luftstroms (Ablenkbleche und Lüfterhalterungen), E/A-Ausschnitte, Netzteiloptionen und Frontlaufwerk-Layouts, die auf Ihr Einsatz- und Servicemodell abgestimmt sind.
Was sollte ich in meiner Anfrage angeben, um eine genaue Empfehlung zu erhalten?
Geben Sie GPU-Modell und -Anzahl, erwartete GPU-Leistung (TDP), CPU-Plattform/Platinengröße, NIC-Typ und -Anzahl, benötigte Laufwerksschächte (SAS/SATA/NVMe), Einschränkungen der Racktiefe und Anforderungen an die Netzteilredundanz an.