
Inicio → Maletín para servidores GPU → Aplicaciones
Casos prácticos de servidores GPU
Adapte su carga de trabajo a los requisitos adecuados del chasis del servidor de GPU: refrigeración, expansión PCIe, suministro de energía, almacenamiento y capacidad de servicio. Esta página cubre el entrenamiento de IA, la inferencia de IA, HPC y las implementaciones adyacentes aceleradas por GPU.
Visión general
Utilice estos puntos de comprobación antes de seleccionar una familia de chasis:
- Perfil de la carga de trabajo: formación sostenida frente a inferencia en ráfagas frente a trabajos HPC de larga duración.
- Número de GPU y factor de forma: doble ranura, longitud/altura de la tarjeta y espacio libre del conector.
- Objetivo térmico: integridad del flujo de aire de adelante hacia atrás, capacidad de la pared del ventilador y diseño del deflector.
- Disposición PCIe: GPUs + NICs de alta velocidad + HBAs de almacenamiento sin bloqueo del flujo de aire.
- Operaciones: bahías de intercambio en caliente, acceso sin herramientas, raíles y flujo de servicio en el bastidor.
Aplicaciones / Casos prácticos
Formación en IA (LLM / CV / Multimodal)
Puntos de dolor
- Estrangulamiento térmico durante la carga sostenida de la GPU.
- El cableado denso y los nodos pesados ralentizan el servicio.
- Las GPU y las NIC compiten por el espacio y el flujo de aire.
Requisitos
- Pared del ventilador de alta presión estática y deflectores de flujo de aire.
- Diseño limpio de la fuente de alimentación para el suministro de energía a varias GPU.
- Acceso frontal de servicio para ventiladores y accionamientos.
Métricas clave
- Capacidad de la GPU y espacios libres (longitud/altura/anchura).
- Espacio libre de refrigeración con una utilización sostenida.
- Potencia de la fuente de alimentación y disponibilidad del conector de alimentación de la GPU.
- Plan PCIe para ranuras x16, elevadores y colocación de NIC.
Configuración recomendada
- Chasis de clase 6U/8U para una mayor densidad de GPU (sujeto al tamaño de la GPU y los térmicos).
- Opciones de fuente de alimentación redundante, pared de ventiladores y deflectores dedicados.
- Bahías frontales de intercambio en caliente para el sistema operativo y la caché local.
Inferencia de IA (Edge / On-Prem)
Puntos de dolor
- Límites de profundidad de las estanterías y espacios reducidos.
- Mayor temperatura ambiente y polvo en entornos mixtos.
- Necesidad de ciclos de sustitución rápidos para operaciones de flota.
Requisitos
- Chasis compacto con flujo de aire estable y acceso frontal.
- Admite de 1 a 4 GPU, además de bahías de almacenamiento para registros y caché.
- Robustos raíles/manillas para un despliegue frecuente.
Métricas clave
- Profundidad del chasis y rango de extensión de los raíles.
- Rendimiento de refrigeración en condiciones ambientales más elevadas.
- Eficiencia energética con el rendimiento objetivo.
- E/S e indicadores frontales para una rápida localización de averías.
Configuración recomendada
- Chasis de clase 4U para nodos de GPU compactos (sujeto al tamaño de la GPU y los térmicos).
- Bahías intercambiables en caliente para un mantenimiento rápido en el bastidor.
- Filtro de polvo opcional y diseño frontal reforzado.
HPC (Simulación / Investigación / Computación científica)
Puntos de dolor
- Los trabajos de larga duración amplifican el coste de la inestabilidad y los fallos.
- Las NIC de alta velocidad compiten con las GPU por el espacio PCIe y el flujo de aire.
- Los distintos laboratorios tienen normas diferentes para los bastidores y el mantenimiento.
Requisitos
- Flujo de aire predecible de adelante hacia atrás y opciones de redundancia de ventiladores.
- Diseño PCIe limpio para GPU y redes de alta velocidad.
- Acceso sin herramientas y arquitectura de ventilador/accionamiento reparable.
Métricas clave
- Recuento de ranuras FHFL y orientación del elevador.
- Preparación y autorización de la generación PCIe para NIC.
- Margen térmico bajo utilización sostenida del 100%.
- Objetivos de redundancia y fiabilidad general de la fuente de alimentación.
Configuración recomendada
- Chasis de clase 5U/6U para una densidad y expansión equilibradas.
- Espacio para GPUs + NICs con mínima interrupción del flujo de aire.
- Soportes de ventilador centrales opcionales para proteger las zonas de NIC/memoria.
Renderización / VDI / Digital Twin
Puntos de dolor
- Los picos de demanda pueden desencadenar puntos calientes e inestabilidad.
- La densidad multiusuario aumenta el estrés energético y de refrigeración.
- Los activos de gran tamaño requieren caché local u opciones de almacenamiento rápido.
Requisitos
- Flujo de aire uniforme en todas las GPU con deflectores.
- Bahías intercambiables en caliente para mayor eficiencia de caché y mantenimiento.
- Rieles aptos para configuraciones de GPU pesadas.
Métricas clave
- Espaciado de la GPU y consistencia del flujo de aire.
- Número de bahías de unidad y tipo de placa base (SAS/SATA/NVMe).
- Selección de la fuente de alimentación y estrategia de redundancia.
- Indicadores frontales y tiempo de acceso al servicio.
Configuración recomendada
- Chasis de clase 6U para una mayor densidad de GPU (sujeto al tamaño de la GPU y los térmicos).
- Opción de fuente de alimentación redundante para un funcionamiento continuo.
- Bahías frontales de intercambio en caliente para intercambios rápidos en granjas.
GPU Analytics & Data Pipelines (ETL / Vídeo / Búsqueda)
Puntos de dolor
- El ancho de banda de almacenamiento y la topología PCIe pueden convertirse en cuellos de botella.
- Muchas unidades + GPU aumentan la complejidad de los cables y el acoplamiento térmico.
- Las operaciones 24×7 requieren un servicio rápido y repetible.
Requisitos
- Placa base y bahías intercambiables en caliente para simplificar el funcionamiento.
- Espacio PCIe para GPU + NIC + HBA según sea necesario.
- Protección del flujo de aire para las zonas de la GPU y las unidades de disco.
Métricas clave
- Número de unidades e interfaz (SAS/SATA/NVMe).
- Recuento de ranuras FHFL y holguras internas.
- Indicadores frontales de almacenamiento y fallos del sistema.
- Tiempo de sustitución del ventilador en el rack.
Configuración recomendada
- Chasis de clase 4U/5U cuando necesite más bahías por unidad de rack.
- Ventiladores potentes y facilidad de mantenimiento frontal.
- Disposición frontal personalizada opcional para diseños con gran cantidad de NVMe.
Lista de selección
Valide el chasis en función de sus limitaciones de implantación y futuras actualizaciones.
| Refrigeración | Capacidad de la pared del ventilador, presión estática, deflectores, espacio térmico de la GPU, montaje opcional preparado para líquido. |
|---|---|
| Flujo de aire | Integridad de canal de adelante hacia atrás, control de obstrucción de cables/riser, mitigación del polvo en lugares difíciles. |
| PCIe | Ranuras FHFL, disposición de risers, espacio libre para GPU de doble ancho, espacio para NIC/HBA, preparación para Gen4/Gen5. |
| Potencia | Factor de forma de la fuente de alimentación (ATX/CRPS), redundancia, margen de potencia, conectores de GPU, diseño de la PDB. |
| Bahías para unidades | Recuento de bahías de intercambio en caliente, tipo de placa base (SAS/SATA/NVMe), ancho de banda y separación del flujo de aire. |
| Placa base | Tamaños de placa compatibles (EATX/CEB/ATX), espacio libre para el disipador de la CPU, espacio para el cableado. |
| Profundidad | Ajuste del bastidor, espacio libre trasero para alimentación/red, radio de curvatura del cable, rango de extensión del carril. |
| Rieles | Capacidad de carga, opciones de instalación sin herramientas, estandarización de flotas. |
| Mantenimiento | Ventiladores/drives de acceso frontal, cubierta superior sin herramientas, indicadores claros, E/S modulares. |
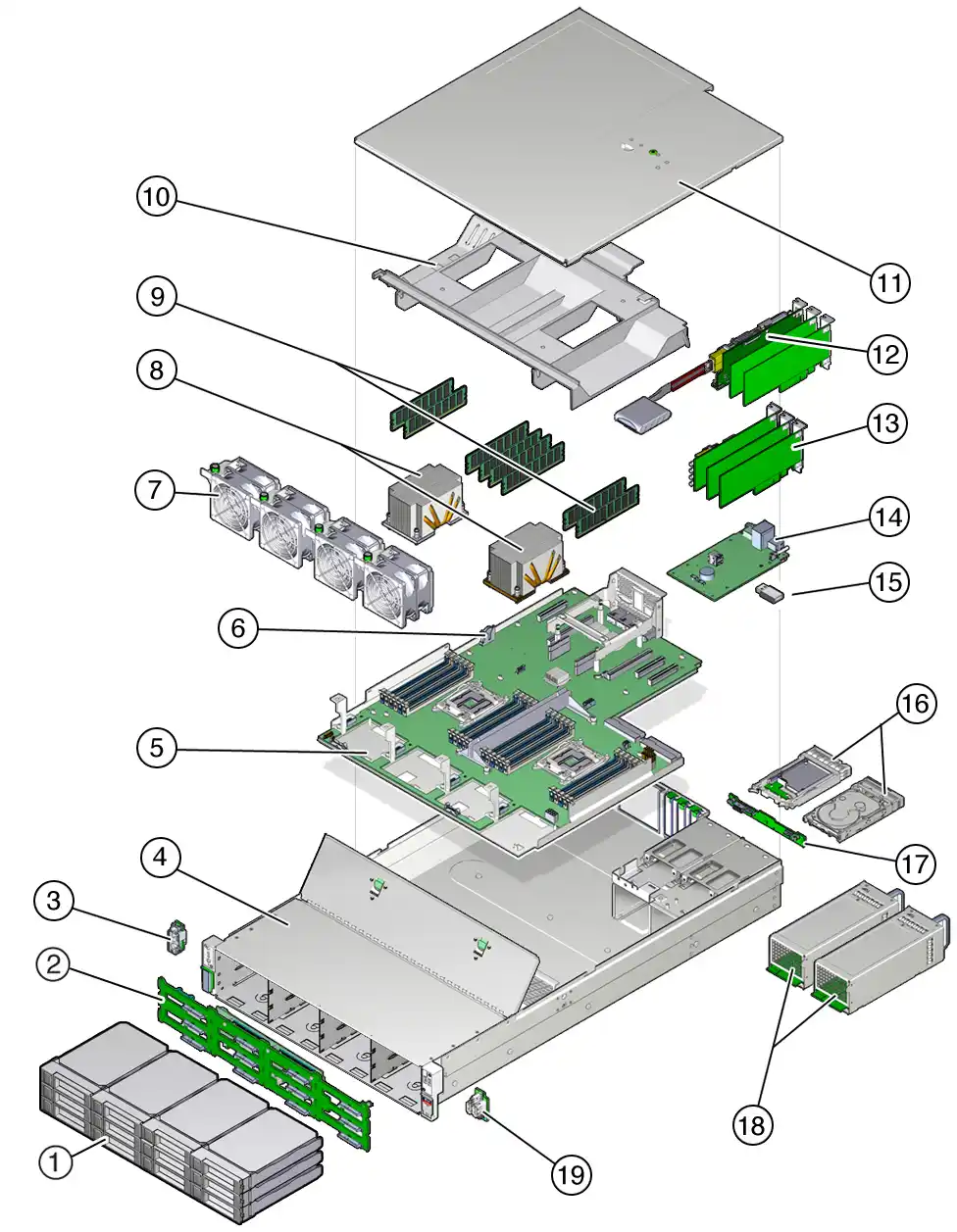
PREGUNTAS FRECUENTES
¿Qué tamaño de chasis es mejor para el entrenamiento de IA?
Empieza por el número de GPU, el tamaño de la GPU y los objetivos térmicos sostenidos. Los nodos de formación suelen favorecer un mayor margen de flujo de aire y capacidad de servicio. Compruébalo con el TDP de tu GPU, la temperatura de entrada al rack y la disposición de PCIe.
¿Cuál es la diferencia clave entre las necesidades de chasis de formación y de inferencia?
La formación hace hincapié en un margen de refrigeración sostenido y una mayor densidad de GPU, mientras que la inferencia suele priorizar la implantación compacta, el ajuste a la profundidad del bastidor y el mantenimiento rápido sobre el terreno. En ambos casos se requiere un diseño limpio de PCIe y alimentación.
¿Cómo evitar el ahogo térmico en servidores multi-GPU?
Utilice un chasis con una pared de ventiladores de alta presión estática, deflectores de flujo de aire y rutas de cables despejadas. Asegúrese de que las GPU y las NIC estén colocadas de forma que se preserve el flujo de aire de delante hacia atrás y no se obstruya la entrada de aire.
¿Qué datos PCIe debo confirmar antes de hacer el pedido?
Confirme el número de ranuras FHFL, la orientación del riser, el espacio libre para GPU de doble ancho y el espacio para NIC de alta velocidad y HBA de almacenamiento. Alinee con antelación la topología del chasis, la placa base y la plataforma para evitar conflictos de carriles.
¿Necesito fuentes de alimentación redundantes para los servidores GPU?
Las opciones de fuente de alimentación redundante se recomiendan para clústeres y flotas centrados en el tiempo de actividad. Dimensione la fuente de alimentación con margen para los peores casos de GPU, CPU, almacenamiento, NIC y ventiladores, y añada un margen de seguridad.
¿Cuándo son importantes las bahías intercambiables?
Las bahías de intercambio en caliente reducen el tiempo de servicio en operaciones multinodo, especialmente para flotas de inferencia, granjas de renderizado y canalizaciones analíticas en las que la sustitución rápida de unidades y el servicio en el bastidor son importantes.
¿Puede iSTONECASE soportar la personalización OEM/ODM para aplicaciones específicas?
Sí. La personalización típica incluye el ajuste del flujo de aire (deflectores y soportes de ventilador), los recortes de E/S, las opciones de fuente de alimentación y las disposiciones de las unidades frontales para adaptarse a su modelo de implantación y servicio.
¿Qué debo incluir en mi consulta para obtener una recomendación precisa?
Indique el modelo y el número de GPU, la potencia prevista de la GPU (TDP), la plataforma/el tamaño de la placa de la CPU, el tipo y la cantidad de NIC, las necesidades de bahías de unidades (SAS/SATA/NVMe), las limitaciones de profundidad del bastidor y los requisitos de redundancia de la fuente de alimentación.