
Home → GPU Server Case → Applications
GPU Server Case Applications
Match your workload to the right GPU server chassis requirements—cooling, PCIe expansion, power delivery, storage, and serviceability. This page covers AI training, AI inference, HPC, and adjacent GPU-accelerated deployments.
Overview
Use these checkpoints before selecting a chassis family:
- Workload profile: sustained training vs bursty inference vs long-running HPC jobs.
- GPU count & form factor: dual-slot, card length/height, and connector clearance.
- Thermal target: front-to-back airflow integrity, fan wall capacity, and baffle design.
- PCIe layout: GPUs + high-speed NICs + storage HBAs without airflow blockage.
- Operations: hot-swap bays, tool-less access, rails, and in-rack service flow.
Applications / Use Cases
AI Training (LLM / CV / Multimodal)
Pain points
- Thermal throttling during sustained GPU load.
- Dense wiring and heavy nodes slow down servicing.
- GPUs + NICs compete for space and airflow.
Requirements
- High-static-pressure fan wall and airflow baffles.
- Clean PSU design for multi-GPU power delivery.
- Front service access for fans and drives.
Key metrics
- GPU capacity and clearances (length/height/width).
- Cooling headroom at sustained utilization.
- PSU wattage and GPU power connector availability.
- PCIe plan for x16 slots, risers, and NIC placement.
Recommended configuration
- 6U/8U class chassis for higher GPU density (subject to GPU size and thermals).
- Redundant PSU options, fan wall, and dedicated baffles.
- Front hot-swap bays for OS and local cache.
AI Inference (Edge / On-Prem)
Pain points
- Rack depth limits and space-constrained sites.
- Higher ambient temperature and dust in mixed environments.
- Need fast replacement cycles for fleet operations.
Requirements
- Compact chassis with stable airflow and front access.
- Support for 1–4 GPUs plus storage bays for logs and cache.
- Robust rails/handles for frequent deployment.
Key metrics
- Chassis depth and rail extension range.
- Cooling performance in higher ambient conditions.
- Power efficiency at target throughput.
- Front I/O and indicators for quick troubleshooting.
Recommended configuration
- 4U class chassis for compact GPU nodes (subject to GPU size and thermals).
- Hot-swap bays for fast servicing in-rack.
- Optional dust filter and reinforced front design.
HPC (Simulation / Research / Scientific Computing)
Pain points
- Long-running jobs amplify the cost of instability and failures.
- High-speed NICs compete with GPUs for PCIe space and airflow.
- Different labs have different standards for racks and maintenance.
Requirements
- Predictable front-to-back airflow and fan redundancy options.
- Clean PCIe layout for GPUs + high-speed networking.
- Tool-less access and serviceable fan/drive architecture.
Key metrics
- FHFL slot count and riser orientation.
- PCIe generation readiness and clearance for NICs.
- Thermal margin under sustained 100% utilization.
- PSU redundancy and overall reliability targets.
Recommended configuration
- 5U/6U class chassis for balanced density and expansion.
- Room for GPUs + NICs with minimal airflow disruption.
- Optional mid-fan brackets to protect NIC/memory zones.
Rendering / VDI / Digital Twin
Pain points
- Peak demand bursts can trigger hotspots and instability.
- Multi-user density increases power and cooling stress.
- Large assets require local cache or fast storage options.
Requirements
- Consistent airflow across all GPUs with baffles.
- Hot-swap bays for cache and maintenance efficiency.
- Rails rated for heavy GPU configurations.
Key metrics
- GPU spacing and airflow consistency.
- Drive bay count and backplane type (SAS/SATA/NVMe).
- PSU selection and redundancy strategy.
- Front indicators and service access time.
Recommended configuration
- 6U class chassis for higher GPU density (subject to GPU size and thermals).
- Redundant PSU option for continuous operation.
- Front hot-swap bays for fast swaps in farms.
GPU Analytics & Data Pipelines (ETL / Video / Search)
Pain points
- Storage bandwidth and PCIe topology can become bottlenecks.
- Many drives + GPUs increase cable complexity and thermal coupling.
- 24×7 operations require quick and repeatable servicing.
Requirements
- Backplane and hot-swap bays for operational simplicity.
- PCIe room for GPUs + NICs + HBAs as needed.
- Airflow protection for both GPU and drive zones.
Key metrics
- Drive bay count and interface (SAS/SATA/NVMe).
- FHFL slot count and internal clearances.
- Front indicators for storage and system faults.
- Fan replacement time in-rack.
Recommended configuration
- 4U/5U class chassis when you need more bays per rack unit.
- Strong fan arrays and clean front serviceability.
- Optional custom front layout for NVMe-heavy designs.
Selection Checklist
Validate the chassis against your deployment constraints and future upgrades.
| Cooling | Fan wall capacity, static pressure, baffles, GPU thermal headroom, optional liquid-ready mounting. |
|---|---|
| Airflow | Front-to-back channel integrity, cable/riser obstruction control, dust mitigation for harsh sites. |
| PCIe | FHFL slots, riser layout, double-width GPU clearance, NIC/HBA room, Gen4/Gen5 readiness. |
| Power | PSU form factor (ATX/CRPS), redundancy, wattage headroom, GPU connectors, PDB design. |
| Drive Bays | Hot-swap bay count, backplane type (SAS/SATA/NVMe), bandwidth and airflow separation. |
| Motherboard | Supported board sizes (EATX/CEB/ATX), CPU cooler clearance, cable routing space. |
| Depth | Rack fit, rear clearance for power/network, cable bend radius, rail extension range. |
| Rails | Load rating, tool-less install options, fleet standardization. |
| Maintenance | Front-access fans/drives, tool-less top cover, clear indicators, modular I/O. |
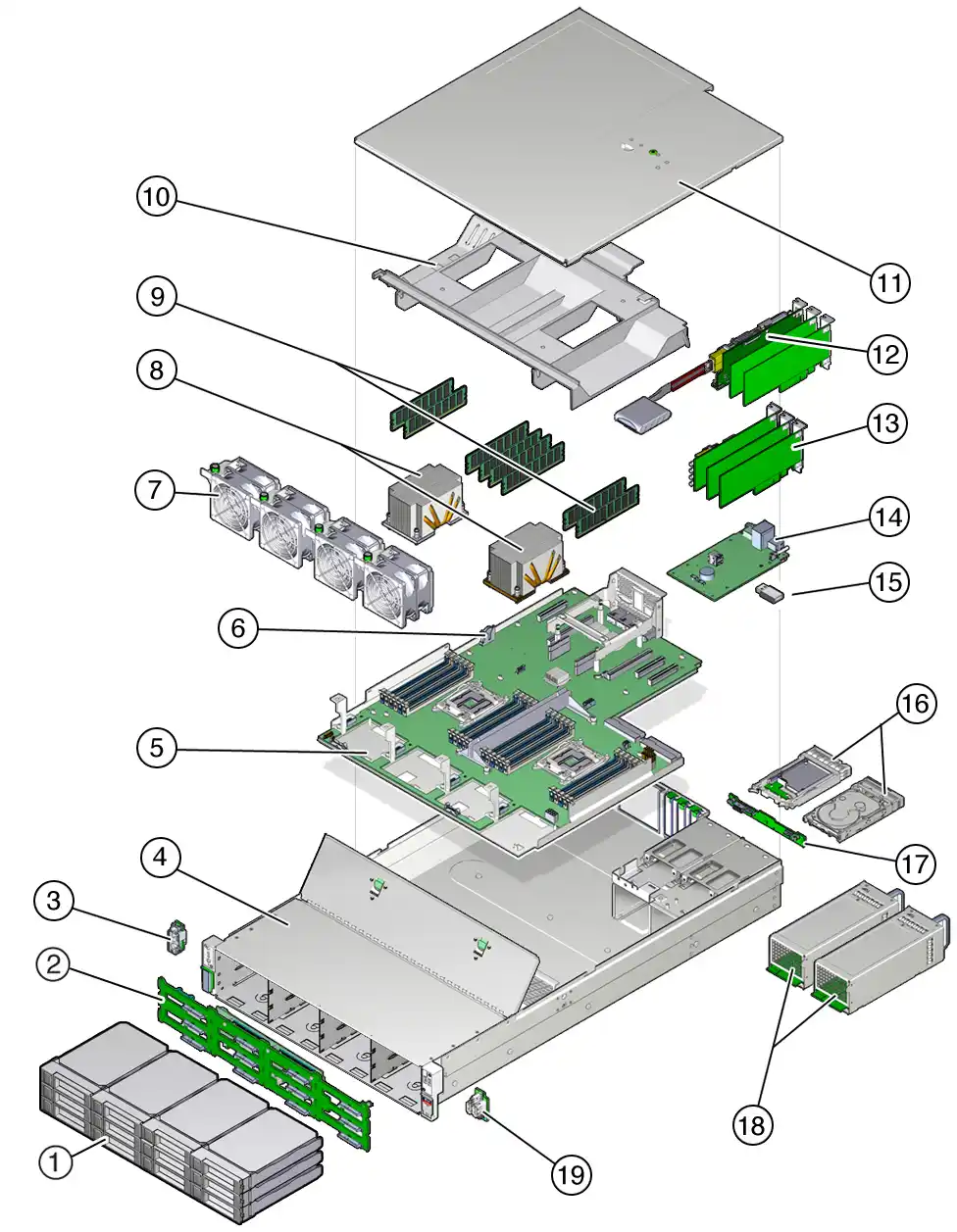
FAQ
Which chassis size is best for AI training?
Start from GPU count, GPU size, and sustained thermal targets. Training nodes typically favor higher airflow headroom and serviceability. Validate with your specific GPU TDP, rack inlet temperature, and PCIe layout.
What is the key difference between training and inference chassis needs?
Training emphasizes sustained cooling margin and higher GPU density, while inference often prioritizes compact deployment, rack depth fit, and fast field servicing. Both still require clean PCIe and power design.
How do I avoid thermal throttling in multi-GPU servers?
Use a chassis with a high-static-pressure fan wall, airflow baffles, and clear cable paths. Ensure GPUs and NICs are placed to preserve front-to-back airflow and keep intake air unobstructed.
What PCIe details should I confirm before ordering?
Confirm FHFL slot count, riser orientation, double-width GPU clearance, and room for high-speed NICs and storage HBAs. Align chassis, motherboard, and platform topology early to avoid lane conflicts.
Do I need redundant power supplies for GPU servers?
Redundant PSU options are recommended for uptime-focused clusters and fleets. Size the PSU with headroom for worst-case GPU, CPU, storage, NICs, and fans—then add safety margin.
When are hot-swap bays important?
Hot-swap bays reduce service time in multi-node operations, especially for inference fleets, rendering farms, and analytics pipelines where quick drive replacement and in-rack service matter.
Can iSTONECASE support OEM/ODM customization for specific applications?
Yes. Typical customization includes airflow tuning (baffles and fan brackets), I/O cutouts, PSU options, and front drive layouts to match your deployment and service model.
What should I include in my inquiry to get an accurate recommendation?
Provide GPU model & count, expected GPU power (TDP), CPU platform/board size, NIC type and quantity, drive bay needs (SAS/SATA/NVMe), rack depth constraints, and PSU redundancy requirements.